[번역] Large-Scale Multilingual Speech Recognition with a Streaming E2E model
원본은 post는 original-google-post 여기를 보시면 됩니도.
아직은 많은 언어들이 데이터가 부족하지요. 데이터가 많이 없는 언어에 대해서도 음성인식기의 퀄리티를 높게 가져가고 싶어요. 데이터가 많은 언어의 지식을 데이터가 적은 언어들에서 재사용할 수 있을까 -> multilingual speech recognition 연구 (하나의 모델로 여거 언어를 인식)
2019 interspeech에서 발표한 해당 논문은 실시간 다국어 인식을 위한, 하나의 모델로 훈련하는 e2e 시스템 9개의 인도 언어를 사용해서 데이터가 많은 언어 뿐만아니라 데이터가 별로 없는 여러가지 언어들에 대해 드라마틱한 성능향상이 있었어요.
인도언어
- 본질적으로 30개 이상의 다양한 언어를 수많은 사람들이 쓰는 언어
- 지리적인 이유와 공유되는 문화 역사때문에 이 언어들의 많은 경우가 acoustic and lexical(사전적인, 어휘적인) content가 겹쳐요.
- 많은 인도사람들이 bilingual ot trilingual이라서 대화속에 여러 언어가 섞여 있어요.
- 따라서 인도언어는 하나의 multilingual model을 학습하기에 자연스러운 케이스입니다.
- 이 작업에서 우리는 9개의 주요 인도언어를 같이 사용했습니다. (Hindi, Marathi, Urdu, Bengali, Tamil, Telugu, Kannada, Malayalam and Gujarati)
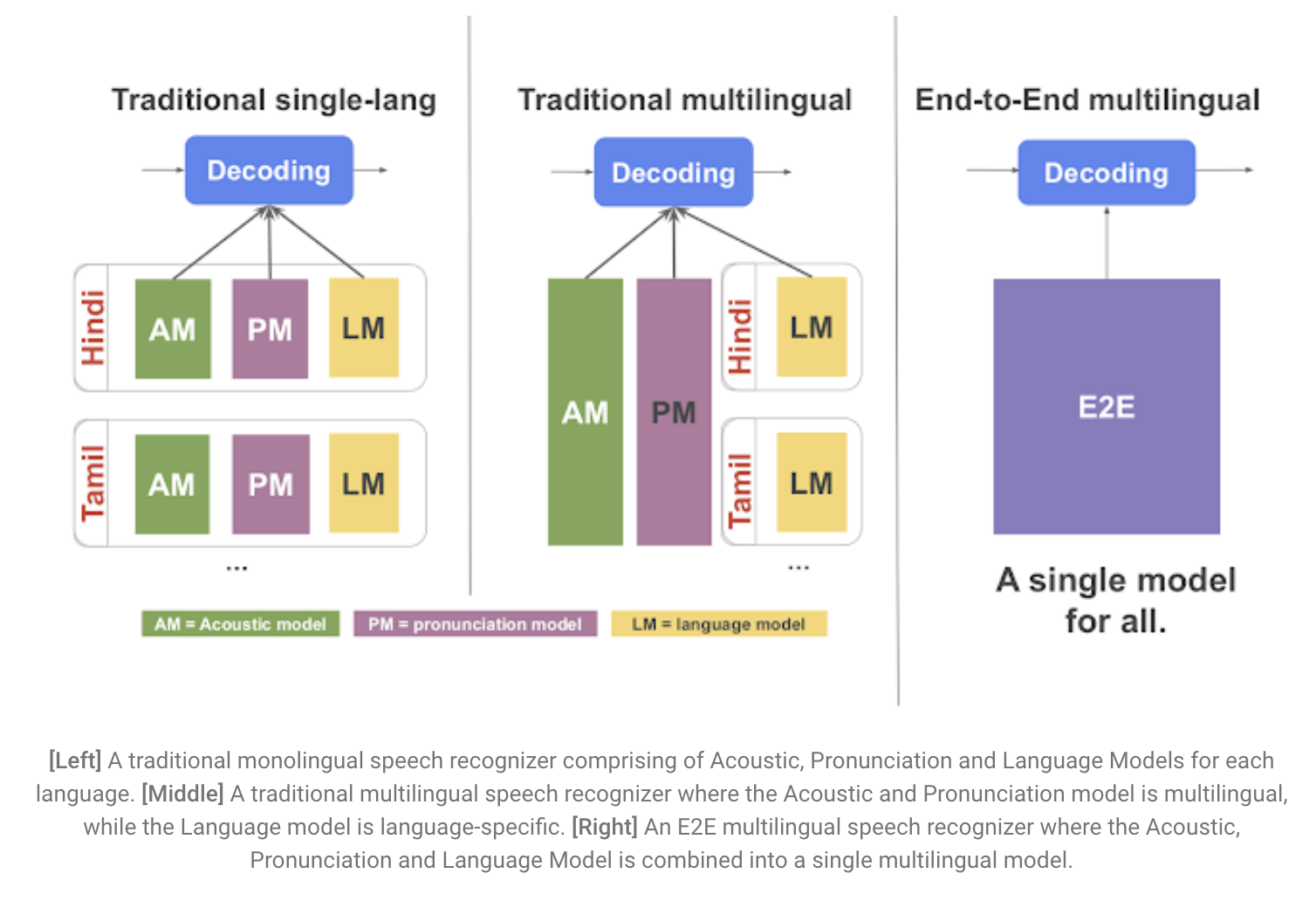
A Low-latency All-neural Multilingual Model
- 기존 음성인식 시스템은 분리된 AM, PM, LM의 결합체 -> multilingual로 만들기가 복잡하고 확장하는게 어려워요.
- E2E model은 이 세개를 모두 하나의 네트워크로 넣어서 scalability(확장성)와 parameter sharing에 용이
- 근데 기존 E2E multilingual model들은 real-time speech recognition이 안되었었어요.
- 그래서 streaming E2E ASR을 만들기 위해 RNN-T(Recurrent Neural Network Transducer)를 사용
- RNN-T 는 실제로 실시간으로 타이핑을 하는 것 처럼 한번에 한 글자씩 단어를 내뱉음 (* 한글자? 단어? 뭐), 근데 이건 multilingual이 아님
- 그래서 우리는 이 구조(RNN-T) 위에서 실험 for low-latency model for multilingual speech recognition.
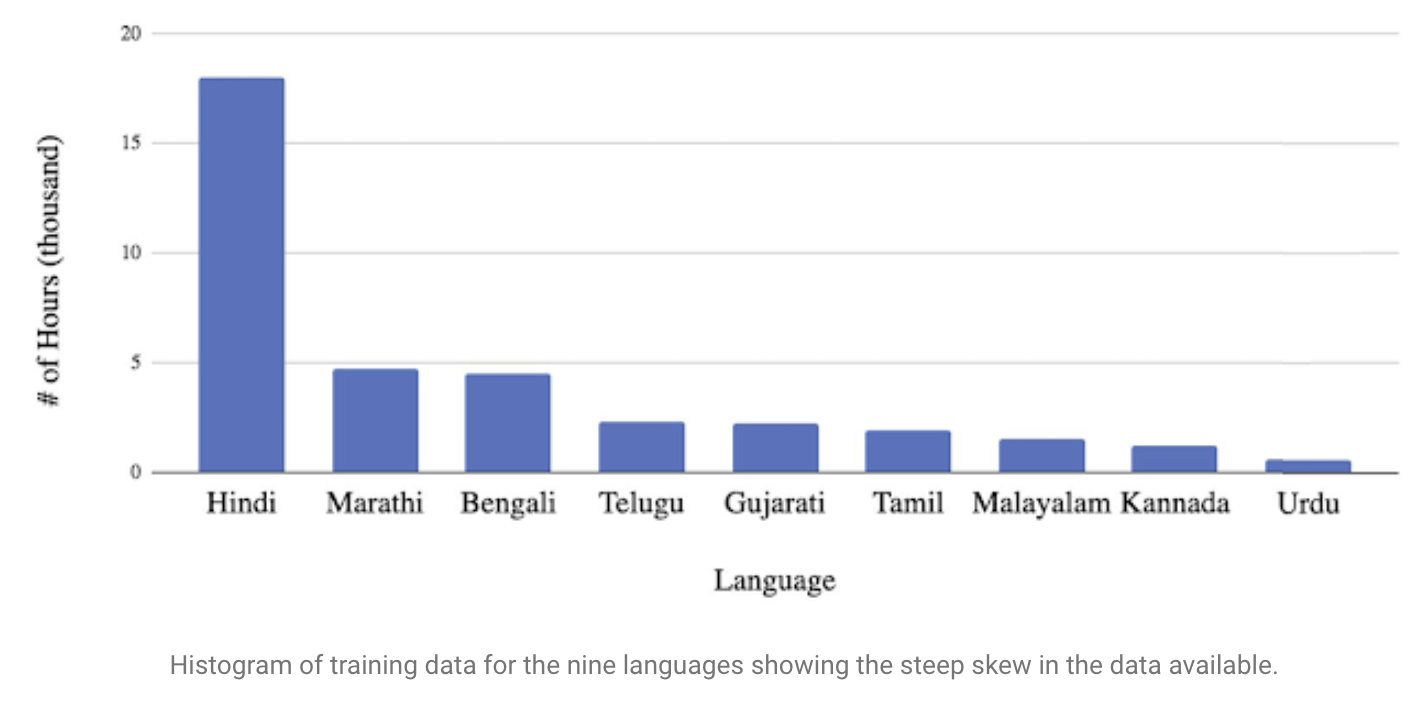
Large-Scale Data Challenges
- large-sclae이고 real-world data를 써서 multilingual model을 훈련하려면 data imbalance 때문에 복잡해요.
- 언어마다 사용가능한 자원의 양이 아주 다르죠.
- 그래서 training set에 data가 많은 언어에 의해 model이 영향을 더 많이받겠죠.
- 이러한 bias는 기존 음성인식 시스템도다 E2E에서 더 주요합니다.
- E2E는 추가적인 in-language text data를 안쓰고 오직 audia training data로부터 lexical characteristics를 배우기 때문이죠.
- 우리는 이 issue를 몇몇 구조 변경으로 해결했어요.
- 입력에 추가적인 언어식별자를 넣었습니다.
- *training data의 language locale로 부터 derived된 external signal (예, the language preference set in an individual’s phone)
- 이 signal은 audio input과 합쳐져서 one-hot feature vector가 됩니다.
-
- 우리는 모델이 언어를 disambiguate 하기 위한것 뿐만 아니라, 각각의 언어에 대해 각각의 feature를 학습하기 위해 language vector를 사용할 수 있다고 가정했다. data imbalance 문제를 도와주기 위해 필요한거라면.
- global model에서 language-specific representation 아이디어에서, 우리는 네트워크 구조를 좀 더 확장했어요.
-
- residual adapter modules의 형태로 각 언어별로 allocating extra parameter 하는 것
- adapters는 single global model의 parameter efficiency를 유지하면서, 각 언어별로 global model을 fine-tune 하는데에 도움을 줍니다. 그리고 결과적으로 성능도 향상이 됩니다.
- residual adapter modules의 형태로 각 언어별로 allocating extra parameter 하는 것
- 입력에 추가적인 언어식별자를 넣었습니다.
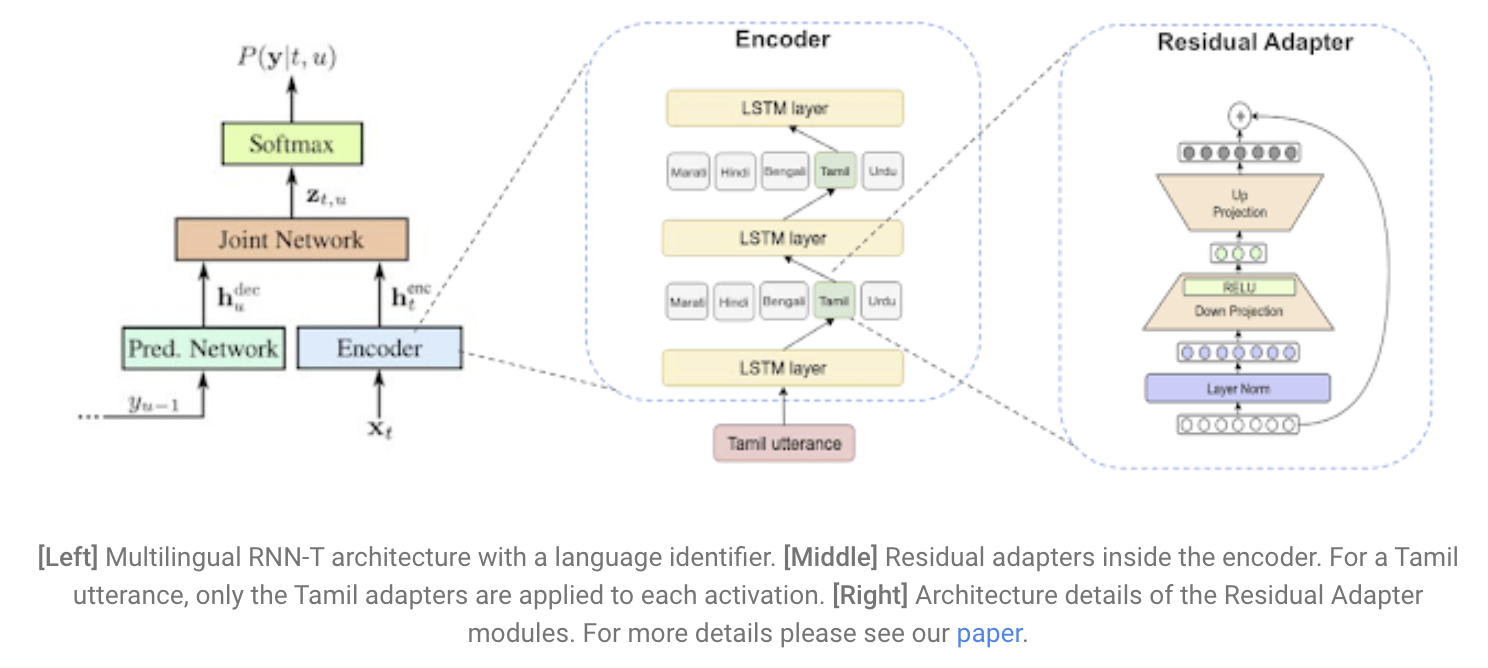
이 세개의 elements들을 모두 같이 써서 우리 multilingual model은 모든 단일언어 음성인식기의 성능을 뛰어넘었어요. 특히 데이터가 별로 없는 언어들에서는 성능향상이 많이 되었어요. (Kannada and Urdu 언어) 게다가 이건 streaming E2E model이라서 training과 serving이 간단하고 low-latency application에서도 사용할 수 있어요. 앞으로는 다른 언어그룹들에 대해서도 해볼겁니다.