[번역] An Intuitive Explanation of Connectionist Tempral Classification (CTC)
원본은 post는 original-ctc-post 여기를 보시면 됩니다.
https://towardsdatascience.com/intuitively-understanding-connectionist-temporal-classification-3797e43a86c
CTC loss와 decoding operaion을 통한 Text recognition
컴퓨터를 통해 글자를 인식하려고 한다면 Neural Network이 성능에서 가장 좋은 선택이 될거다. 글자 인식의 경우에 CNN은 sequence의 feature를 추출하기 위해 사용하고, RNN은 이 sequence를 통해 정보를 propagate 하는데에 사용된다. RNN의 ouptut은 각 sequence element에 대한 각각에 대한 character-score가 나온다. 그리고 이건 matrix를 통해 간단하게 나타난다. 이 matrix를 가지고 우리가 원하는 두가지를 살펴봅시다.
- 학습: NN을 학습하기 위해 loss를 계산
- infer: input image에 있는 문자를 얻기위해서 matrix를 decode 두 task 모두 CTC operation으로 달성할 수 있다. handwriting recognition system이 그림1에 있다.
CTC operation을 자세히 살펴보고 이게 복잡한 공식에 기반한 엄청난 아이디어를 숨겨놓는것 없이 어떻게 동작하는지 이야기해봅시다.
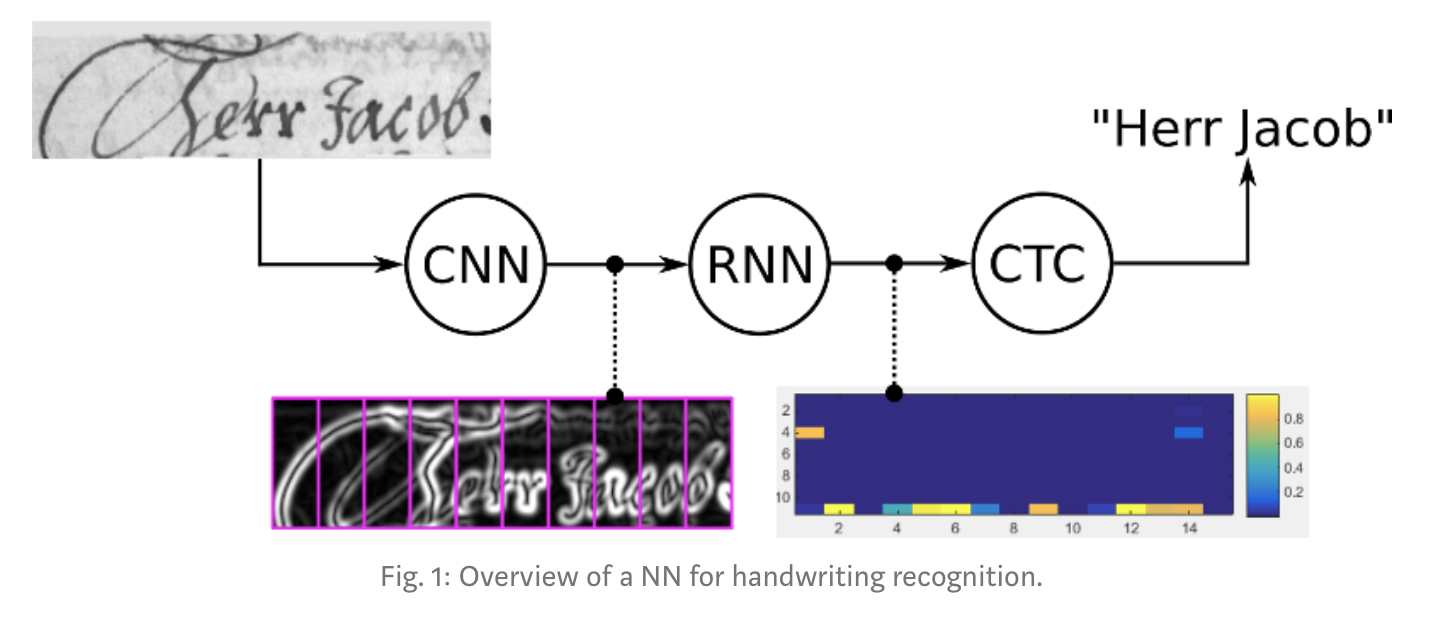
우리는 왜 CTC를 쓰려고 할까나 물론 우리는 text-lines의 image로 되어 있는 data-set을 만들고 이미지의 각 세로축쪽이 나타내는게 뭔지 찾아낼 수 있다. 그림2처럼. 이렇게 하려면 각 세로선 위치에 따라 NN이 character-score을 내놓도록 학습시킬 수 있다. 그러나, 이렇게 하면 두가지 문제가 있다.
- data-set의 character-level의 annotation을 붙이는게 엄청 시간이 많이 든다.
- 이렇게 하면 딱 character-scores밖에 못 얻으니까, 최종 글자를 얻으려면 추가작업을 더 해야한다. 하나의 글자가 여러개의 horizontal position에 걸쳐있을 수 있다. 그래서 겹치는걸 제거해줘야하고. 근데 실제로 겹치는 스펠링을 가진 단어면 어떡해? 예를들어, too 이런거. 이런 경우에는 oo를 지워버리고 o로 하면 틀린 답이 나오잖아요. 이거 어떡할래?

CTC는 이 두 문제점을 해결했다.
- 우리는 CTC loss funtion 에게 오직 이미지에 나오는 text가 뭔지만 얘기해주면 된다. 그래서 이미지 안에서의 글자의 position이나 width같은건 신경을 안써도 된다.
- 더이상의 추가적인 처리가 필요하지 않다.
CTC는 어떻게 동작하나? 위에서 얘기했듯이, 우리는 각 time-step별로 이미지의 annotation을 달아주는걸 원하지 않아요. NN Training은 CTC loss function에 의해 가이딩될겁니다. 우리는 오로지 NN의 output matrix만 넣어주고 그에 해당하는 정답(Ground-truth) text만 ctc loss function에 넣어주면 됩니다. 그러나 각 character가 어디에서 발생하는지 어떻게 알까요? 걔는 모릅니다. 대신, 이미지에 있는 정답 text의 모든 가능한 alignment에 대해 시도하고 모든 score를 더합니다. 이렇게 하면, alighnment-scores들의 합이 높은 값을 가진다면, 정답 text(GR text)의 점수가 높을겁니다.
Encoding the text “too” 와 같이 반복되는 단어가 있을 때 어떻게 처리하느냐에 대한 이슈가 있습니다. 이 이슈는 blank라고 불리우는 pseudo-character의 도입으로 해결합니다. 이 special character는 앞으로 “-“ 라고 쓰겠어요. 우리는 duplicate-character 문제를 해결하기 위해서 똘똘한 코딩 방법을 쓸거예요: text를 encodding 할 때 임의로 많은 blank를 아무 자리에다가 넣을 수 있습니다. 얘는 decoding 할 때 없어질거구요. 그러나 “hello” 과 같이 duplicate character 사이에는 blank를 꼭 넣어야 합니다. 우리는 각각의 charater를 원하는 만큼 반복할 수도 있습니다.
예시를 살펴봅시다.
- “to” —> “—tttttttooo”, or “-t-o-“, or “to”
- “too” —> “—ttttttto—“, or “-t-o-o-“, or “to-o”, but NOT “too” 보다시피 이 방법은 같은 text에 대해서 쉽게 여러가지 다른 alignments를 만들 수 있습니다. 예를들어 “t-o” and “too” and “-to” 모두 “to”라는 같은 text를 나타내는 것이죠. NN은 encoded text를 output으로 내도록 훈련됩니다.(*NN output matrix에서 encoded된 text)
Loss 계산 NN을 학습하기 위해서 training samples (pairs of images and GT texts)의 loss 값을 계산해야 한다. NN의 output은 각 time-step에서의 각 character들의 score를 담고 있는 matrix라는걸 알것이다. minimalistic matrix는 아래 그림3과 같다. 그림3: 두개의 time step (t0, t1)이 있고 3개의 characters (“a”, “b”, and the blank “-“)가 있다. 각 time-step에서 character-scores의 합은 2이다.
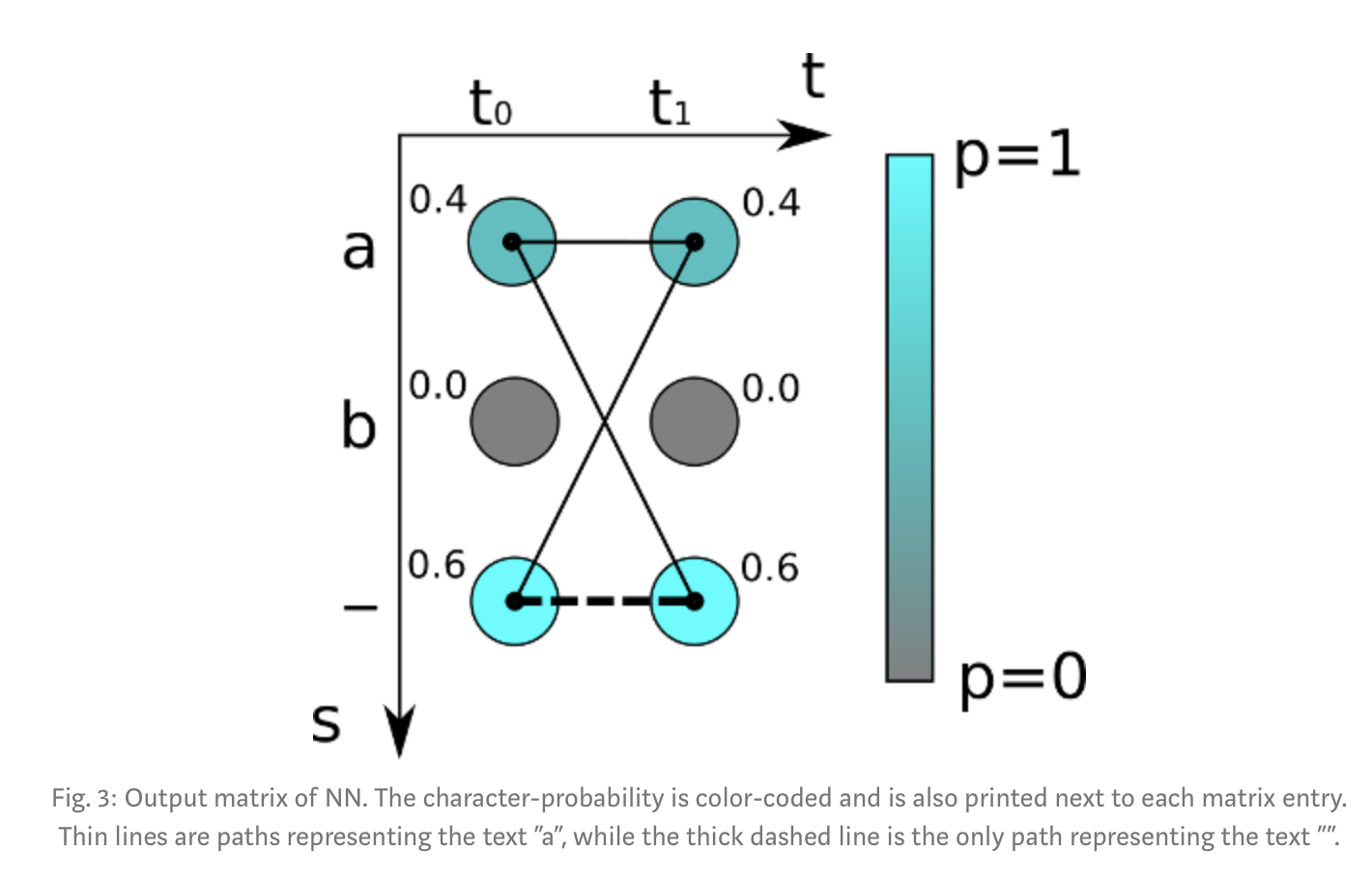
알다시피 loss는 정답 text의 모든 가능한 alignment들의 scores를 모두 더해서 계산하는것이기 때문에, 이 방법은 image에서 text가 어디에 나오는지는 중요하지 않다. (*)
path라고 불리우는 한 alignment의 score는 일치(대응)하는 character scores를 곱해서 나온다. 위의 예시로 보면, “aa” path의 score는 0.40.4=0.16이고, “a-“는 0.40.6=0.24, “-a”는 0.60.4=0.24이다. 주어진 GT text에 대한 score를 얻기 위해서, 우리는 이 text에 대응하는 모든 paths의 score를 더한다. 예시에서 GT text가 “a”라고 가정해보자. : matrix가 2 time-step을 가지고 있기 때문에, 우리는 모든 가능한 길이 2의 path를 계산해야한다. 그거는 “aa”, “a-“, “-a” 가 있다. 그러면 0.40.4 + 0.40.6. + 0.60.4 = 0.64 가 된다. 만약에 GT text가 “”라고 가정한다면 우리는 “- -“에 대응되는 경우 한가지만 고려하면 되고, 이것의 score는 0.6*0.6=0.36 이 된다.
우리는 이제 NN에 의해 생성된 output matrix가 주어지면, training sample의 GT text의 확률값을 계산할 수 있다. Goal은, 제대로 classification 하기 위해서, NN의 output이 높은 확률값(이상적으로는 1)을 갖도록 학습하는 것이다. 그러므로, 우리는 training dataset에 대해 맞게 classifications 된 애의 확률값의 곲을 가장 크게 되도록 해야한다. 기술적인 이유로, 같은 문제를 re-formulate한다. : loss가 negative num of log-probabilities인 상태에서, training dataset의 loss를 minimize 한다. 만약에 하나의 sample에 대한 loss value가 필요하다면, 간단하게 확률을 계산해서, log를 취하고, 결과값에 - 를 붙이면 된다. NN을 훈련하기 위해서, NN parameters(e.g., convolutional kernels의 weights) 각각에 대해 loss 의 gradient를 계산하고, 파라미터 업데이트에 그걸 쓴다.
Decoding NN을 훈련할 때 우리는 보통 이전에 못본 이미지에서 text를 인식하는데에 사용하길 원한다. 좀 더 기술적인 용어로는, NN의 output matrix가 주어지면 가장 그럴듯한 text를 계산하기를 원한다. 주어진 text에 대해 score를 어떻게 계산하는지에 대한 방법은 당신이 이미 알고있을 것이다. 그러나 이번에는, 우리가 실제로 원하는 것인, 어떤 text도 주지 않는다. 오직 몇 time=steps과 characters만 있다면, 모든 가능한 text에 대해서 작동하도록 해보자. 그러나 practical한 use-cases에서 이건 feasible 하지 않다.
간단하고 가장 빠른 알고리즘은 ‘best path decoding’이다. 이건 2단계를 거친다.
- 각 time-step 마다 가장 그럴듯한 character를 선택해서 best path를 계산한다.
- duplicate charactoer를 먼저 없애고, path에서 모든 blanks를 없애서 undoes the encoding 한다(). 남아있는 represents가 인식된 text이다. (YJ, 아닌데? 그럼 겹치는 character 여전히 생기는데?)
그림 4에 예시가 있다. character는 “a”, “b”. “-(blank)” 이다. time-step은 5이다. 이 matrix에 대해 best path decoder를 적용해보자.: t0에서 가장 그럴듯한 character는 “a”이고, t1, t2에서도 같다. t3에서는 blank character가 가장 높은 score를 가진다. 마지막으로 “b”는 t4에서 가장 확률이 높다. 이러면 path는 “aaa-b”가 된다. 여기서 duplicate characters를 지우면 “a-b”가 되고, 남아있는 path에서 blank를 지우면, “ab”가 인식결과가 된다.
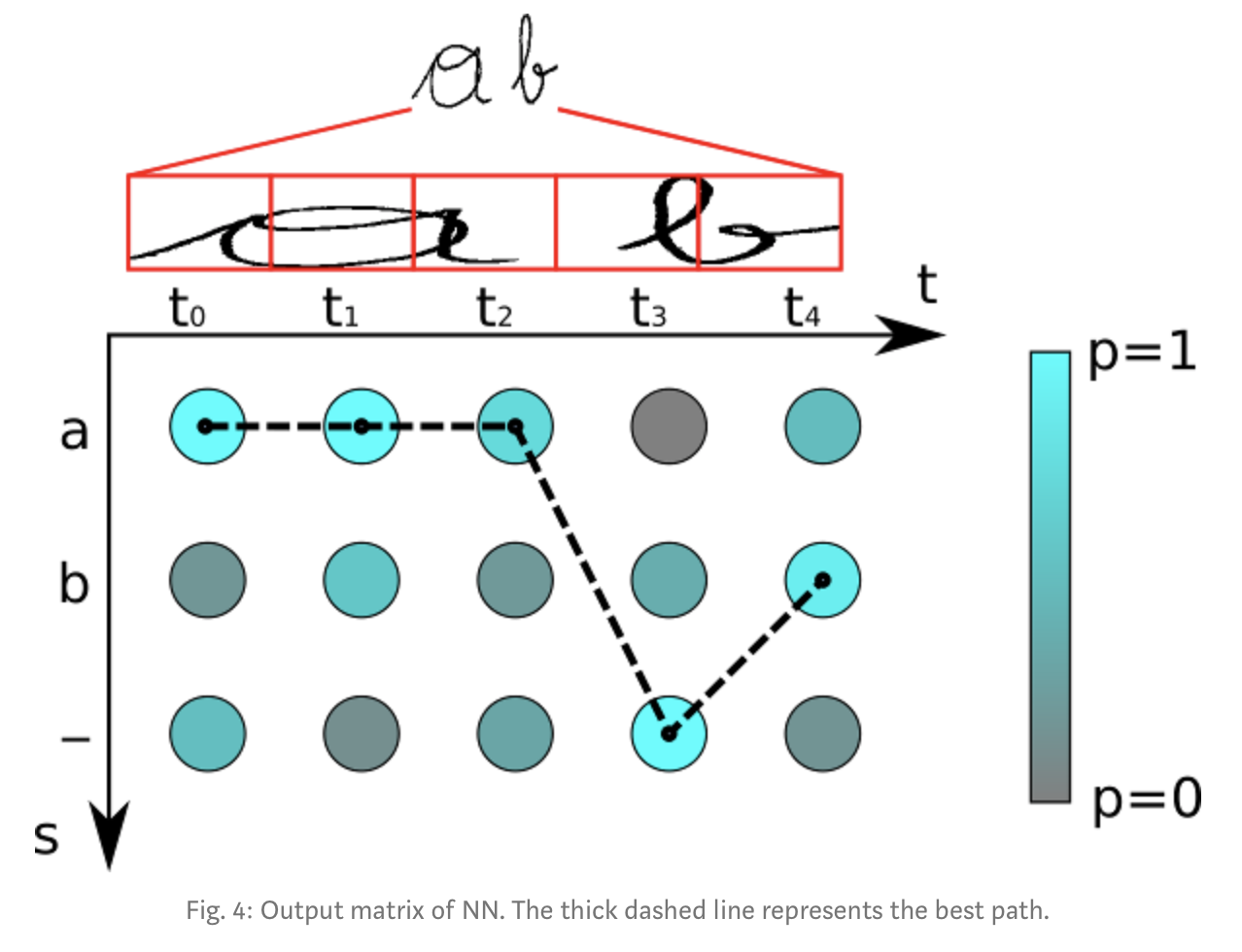
물론 best path decoding (YJ, 이게 greedy search 같은 것을 말하는듯.)은 순전히 approximation이다. 잘못된 결과를 내는 예시는 쉽게 만들 수 있다. : Fig3의 matrix를 decode하려고 한다면, 인식된 결과로 “”를 얻게된다. 하지만 우리는 “”의 확률은 오직 0.36이고, “a”의 확률은 0.64인걸 알고있다. 그러나 실질적인 경우에서 approximation algorithm은 좋은 결과를 낸다. beam-search decoding이나 prefix-search decoding or token passing과 같은 더 좋은 decoder들이 있다. 얘네들도 더 좋은 결과를 내기 위해 language structure에 대한 정보를 사용한다.
Conclusion and further reading 먼저, 우리는 naive NN solution에서 생기는 문제점을 살펴봤다. 그리고 CTC가 이걸 어떻게 해결하는지를 살펴봤다. 그리고는 CTC가 어떻게 text를 encode하고, 어떻게 loss가 계산되는지, 그리고 CTC-trained NN의 output을 어떻게 decoding 하는지를 살펴보면서 CTC가 어떻게 동작하는지 살펴봤다.
이건 TF에서 ctc_loss 함수 혹은 ctc_greedy_decoder를 call 했을 때 뒷단에서 어떻게 동작하는지를 알게해줬을 거예요. 하지만 그대가 직접 CTC 를 구현하려면, 어떻게 하면 더 빨리 동작하는지와 같은 디테일들을 더 알아야겠죠. [1] 논문은 CTC operation에 대해 소개하고 관련된 수학에 대해 보여준다. 만약에 decoding을 발전시키는데에 관심이 있다면 beam search decoding에 대해서 적어놓은 [2],[3] article을 보세요. 이 포스트의 원 저자가 decoder 몇개와 loss function을 python 과 c++로 구현해놨으니 [4],[5] github에서 찾을 수 있어요. 마지막으로, 그대가 손글씨 text를 어떻게 인식하는지에 대한 더 큰 그림을 보고싶다면, 저자의 손글씨 인식기 시스템[6] 글을 보면 됩니다.