[번역] IBM Research advances in e2e speech recognition @INTERSPEECH 2019
원본은 post는 original-IBM_interspeech2019-post 여기를 보시면 됩니다.
E2E ASR은 여러 장점을 가진 NN-based speech recognition계에서 떠오르는 패러다임이다. 기존 hybrid ASR 시스템은 이래저래 훈련 복잡한데 E2E는 하나의 *low audio frame rates에서 동작하는 하나의 간단한 파이프라인만 거치면 되는, single integrated approach이다. 얘는 훈련시간, 디코딩시간을 줄이고 NLU(understanding)와 같은 downstream processing과의 joint optimization도 가능하다.
그치면 현재의 e2e ASR은 몇가지 중요한 한계를 맞닥드리고 있다.
- hybrid ASR 시스템하고 비슷한 성능을 내려면 e2e는 훨 많은 데이터가 필요하다. 왜냐면 데이터가 적은 경우에는 overfit 하게 되는 e2e의 경향 때문. (YJ. hybrid보다 이게 심하다는거지? 데이터를 더 generalize 해줘야 하는건가봄)
- E2E ASR에서 많이 쓰는 CTC가 ensembling 할때랑 teacher-student transfer learning 할 때 수정할 수가 없다. 이 두개는 좋은 성능을 위해서 유용한건데.
그래서 우리는 interspeech 2019에 이런 E2E 접근방식의 ASR 단점들을 다루기 위해서 3편의 논문을 냈다.
“Forget a bit to learn better: soft forgetting for ctc-based automatic speech recognition”
E2E ASR의 성능이 hybrid ASR의 성능과 비등해졌다. 이건 powerful NN 구조와, WER-related loss ftn, 그리고 graphics/tensor processing unit에 의존한 아주 많은 실험들 덕분이다.
이전까지의 CTC-based E2E ASR 시스템은 blstm 네트웍을 사용하고, 각 time step에서 더 다양한 acoustic context를 잡아내기 위해서 모든 발화에 대해 unroll한 구조일 때 좋은 성능을 냈다. (아래 그림1)
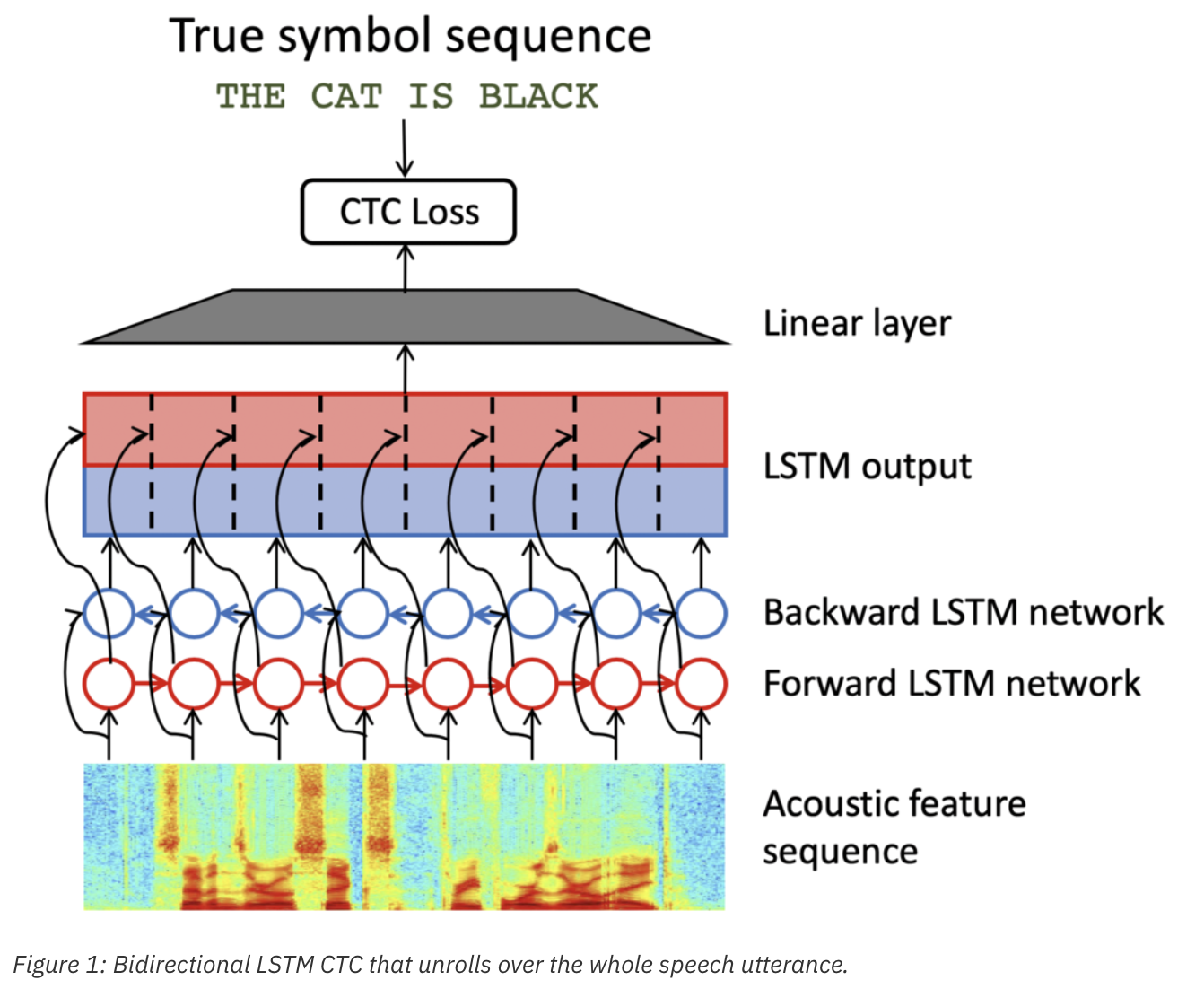
우리는 적은 training data set에 대해서는 특히 overfitting 되는걸 관찰했다. 왜냐면 over-parameterized BLSTM은 training sequence를 외우는게 쉽기 때문이다. 그래서 우리는 이 overfitting을 극복하기위해 soft forgetting을 제안했다.
- input 발화의 non-overlapping chunks 조금만 BLSTM 네트웍을 unroll 했다.
- 고정된 global chunk size 대신 각 배치마다 랜덤하게 chunk size를 선택
- utterance-level의 정보를 얻기위해서 BLSTM의 hidden states를, pretrained 된 전체 utterance BLSTM을 근사하도록 했다. 우리는 training loss ftn에서 추가로 mean-squared error term을 추가로 같이 써서 했다(twin loss). 아래 그림2가 soft forgetting을 요약한 그림
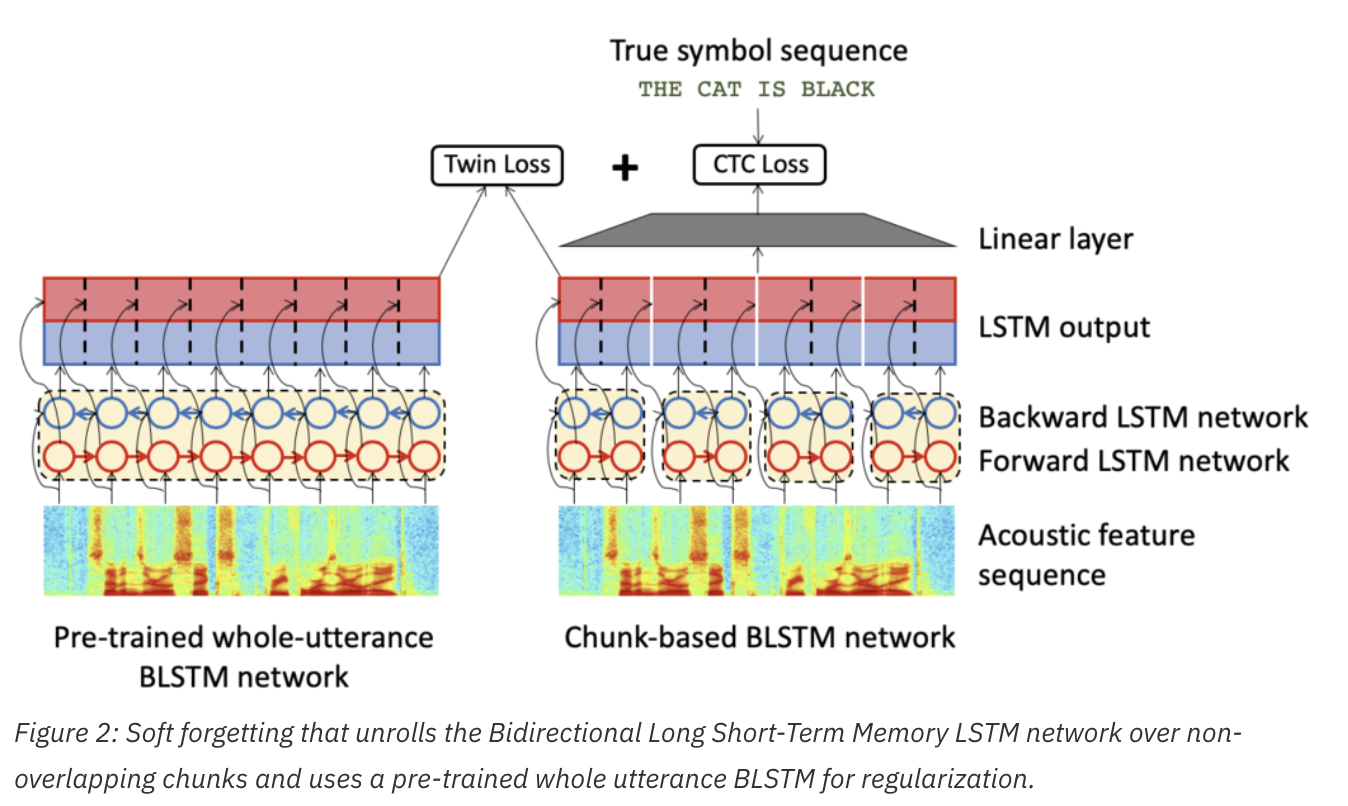
- YJ. non-overlapping chunks 만 unroll 한게 어느부분이지? 정확이 뭐지 그게?
300시간 English switchboard dataset에서 실험 수행. 실험 결과는 soft forgetting이 전체-utterance phone CTC BLSTM보다 relatively 평균 7-9% WER이 향상됨을 보였다. (*YJ. ERR 7-9% 정도면 논문쓸 수 있구나. 오키.) Hub5-2000 switchboard 와 callhome testset에서 각각 speacker-independent WER는 9.1%/17.4% 였고, speaker-adapted model로는 8.7%/16.8% 를 기록했다. 그리고 최신의 offline 과 on-the-fly data augmentation 기술을 접목하니까 speaker-independent phone CTC system에서 7.9%/15.7% 를 기록했다. 이건 speaker-adapted hybrid BLSTM system과 WER이 맞먹는 수준이다. 또한, streaming recognition을 위해 제한된 temporal context를 이용하게 되는 경우에도 soft forgetting으로 WER이 향상됨을 보았다!
“Advancing sequence-to-sequence based speech recognition”
Attention based encoder-decoder 혹은 “all-neural” seq2seq model은 E2E ASR의 대체재적인 접근방식이다. 이 모델들은 input acoustic feature sequence를 encode 하는데에 RNN을 쓰고; encoder outputs에다가 attention weights를 assign하는데에는 attention NN을 쓰고; sequence of symbol(예를들어, character)를 predict하는 데에 RNN decoder를 쓴다. 이 논문에서는 잘 알려지고 공개적으로 쓸 수 있는 db인 librispeech를 사용해서 attention-based 접근방법의 SOTA를 찍어따.
우리 결과는 강력한 Recurrent LM rescoring과 결합한 hybrid model이랑 비교했다. 특히 우리는 seq2seq ASR 모델의 몇가지 기술의 영향에 대해 연구했다: sophisticated data augmentation, 다양한 dropout schemes, scheduled sampling, warm-restart, 다양한 input feature, modeling units, sub-sampling rate, LM, *discriminative training, decoder search configurations.
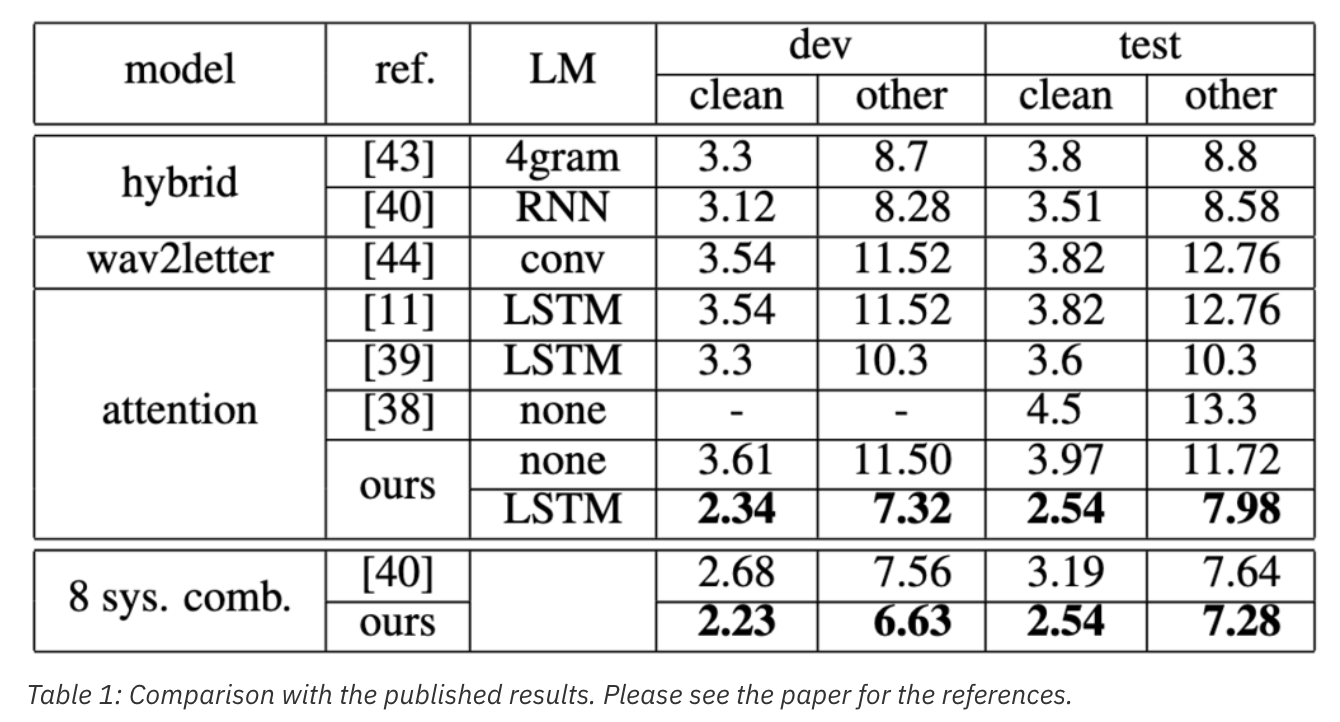
training configuration과 search parameters를 seq2seq ASR model에 대해 optimally 선택하니 attention-based encoder-decoder model의 WER에 상당한 성능향상을 보았다. 여러가지 적용했던 기술들 중에, smaller modeling units와 적당한 application of frame rate reduction이 가장 critical한걸 발견했다. 추가로, straightforward variation in model size, representation unit, input feature의 combination도 추가적인 성능향상이 있었다. 얘네는 encoder-decoder model의 추가적인 potential을 나타낸다. 표1은 librispeech로 테스트 한 다양한 설정의 결과를 보여준다.
“Guiding CTC posterior spike timings for improved posterior fusion and knowldge distillation”
기존 frame-level alignments로 훈련된 ASR시스템은 성능을 높이기 위해서 쉽게 *posterior fusion을 할 수 있고 knowledge distillation으로 더 좋은 단일 모델을 쉽게 만들 수 있었다. CTC loss로 훈련된 e2e asr 시스템은 frame-level alignment를 요구하지 않고, 따라서 model 훈련이 간소화되었다. 그러나, sparse하고 CTC 모델의 모호한 posterior spike timing이 multi model로부터 posterior fusion 할때와 CTC model들 사이에서 knowledge distillation 할 때 어려움을 만들었다.
예를들어 그림3(a)는 uniLSTM phone CTC model을 다른 초기값과 다른 training data 순서로 설정해서 나온 posterior spike 이다. 이거 보면 splike가 aligned 제대로 안되어있다. 그래서 posterior fusion이 잘 동작하지 않는다. 그림3(c)는 uniLSTM과 BiLSTM phone CTC model을 사용한 posterior spikes를 보여주는 그림이다. 완전히 다른 spike timings 때문에 BiLSTM에서 uniLSTM으로의 knowledge distillation은 그냥은 불가능하다.

우리는 CTC model에서 spike timings을 pre-trained guilding CTC model의 그것으로 align 되도록 guide하는 방법을 제안했다. 우리는 이걸 ‘guilded CTC training’이라고 부른다. 그림4를 보면 IniLSTM CTC model의 guilded CTC training의 전형적인 모양이다. 먼저 guilding uniLSTM 모델을 학습시키고, 여러개의 uniLSTM model을 pre-trained guiding model의 spike position과 같게 되도록 학습시킨다. 그 결과, 같은 guiding model을 공유한 모든 모델들은 aligned spike timing을 가졌고, 그래서 그것들의 posterior가 fuse 가능하다. 예를들어, 그림 3(b)에서 밑에 두개의 guided model의 spike는 맨 위에 있는 guiding model의 align이 같다.
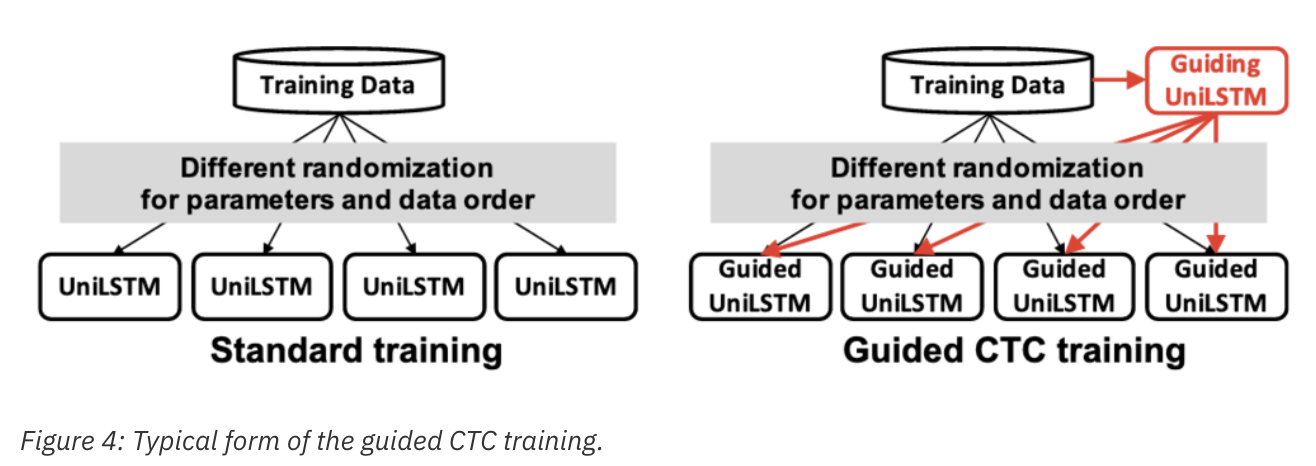
그림5는 제안한 guided CTC training의 schematic diagram이다. matrix의 가로, 세로 축은 각각 time indexes와 output symbol을 나타낸다. 왼쪽의 guided CTC model은 각 time index의 가장 높은 posterior를 가진 output symbol 자리에 1이 표시된 mask를 만든다. 이 mask는 element-wise product를 통해서, 학습된 모델의 posterior에 적용된다. 오른쪽에서 masked posteriors의 합에 -1이 곱해지고, normal CTC loss와 함께 jointly minimized된다.

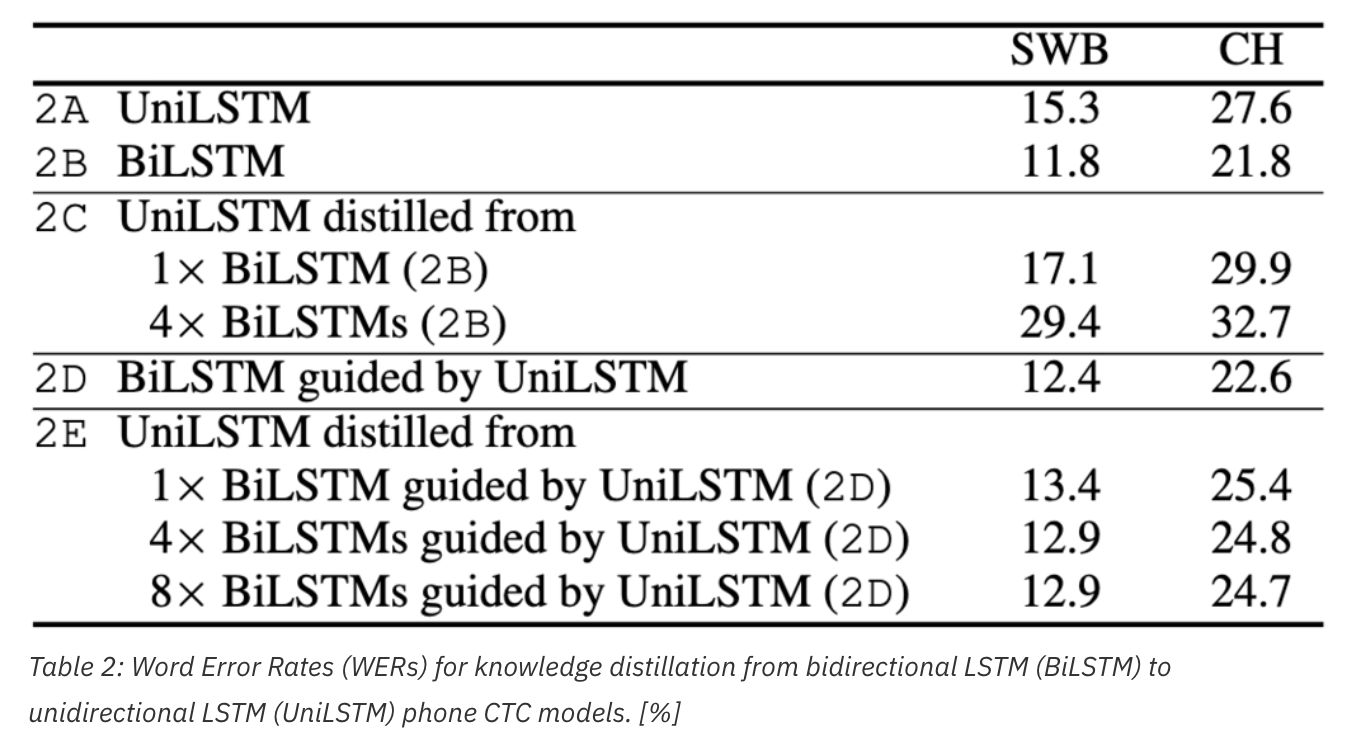
이 논문은 다양한 시나리오 상에서 guilded CTC training의 장점에 대해서 기술했다. BiLSTM phone CTC model을 teacher로 써서 UniLSTM phone CTC model의 성능을 향상시키기 위해 가장 실질적인 중요한 실험을 소개하겠다. 통상 bidirectional 이 성능이 훨씬 좋지만, online streaming application을 만들기 위해서 우리는 unidirectional model만을 사용했다. 우리는 제안한 guided CTC training을 사용해서 BiLSTM CTC model로부터 knowledge distillation을 해서 UniLSTM CTC model을 만드는걸 구현했다. 특히, 우리는 먼저 unidirectional model을 훈련하고 난 후에, 그 unidirectional model을 guiding model로 사용해서 bidirectional model을 훈련했다. (*YJ, uni를 사용해서 bi를 guide 했다고? 반대로 해야하는거 아니고??)
이 approach로 훈련된 bidirectional model 은 unidirectional 과 matched된 spike timing을 가지게 되고, 그로인해 다른 unidirectional model을 훈련하기 위한 teacher로 제공가능하게 되었다. (YJ, 아니 원래 bi가 더 정확하지않음? 왜 uni로 먼저 guide해서 bi를 만들고, 이걸 또 uni의 teacher로 넣지? 그리 3-c 가 보여주듯이 기본적으로 uni 와 bi는 spiking time이 아예 다르기 때문에 uni 성격 맞춰주기 위함인가?) 그림3(d)의 아래 두개 bidirectional model은 맨 위에 있는 guiding unidirectional model과 aligned spike timing을 가지고 있음을 볼 수 있다. ()standard method로 훈련된 bidirectional model의 spike timing은, 제안한 guided CTC training의 spiking time과 완전히 다르다는걸 잘 기억해야한다(그림 3(c)와 (d)를 비교해서 보세요).
아래 표2의 2E 라인을 보면, 이 방식으로 훈련된 unidirectional model이 보통의 unidirectional model인 2A보다 성능이 훨씬 좋음을 볼 수 있다.
*YJ. 그냥 uni로부터 uni distill한거는? (그림 3-b), 그림으로 봐서는 spiking time이 b랑 d랑 차이첨을 잘 모르겠는데??